|
|

|

|
| e-Pub |
Section: New Results
A Hybrid Framework for Online Recognition of Activities of Daily Living In Real-World Settings
Participants : Farhood Negin, Serhan Cosar, Michal Koperski, Carlos Crispim, Konstantinos Avgerinakis, François Brémond.
keywords: Supervised and Unsupervised Learning, Activity Recognition
State-of-the-art and Current Challenges
Recognizing human actions from videos has been an active research area for the last two decades. With many application areas, such as surveillance, smart environments and video games, human activity recognition is an important task involving computer vision and machine learning. Not only the problems related to image acquisition, e.g., camera view, lighting conditions, but also the complex structure of human activities makes activity recognition a very challenging problem. Traditionally, there are two variants of approach to cope with these challenges: supervised and unsupervised methods. Supervised approaches are suitable for recognizing short-term actions. For training, these approaches require a huge amount of user interaction to obtain well-clipped videos that only include a single action. However, Activities of Daily Living (ADL) consists of many simple actions which form a complex activity. Therefore, the representation in supervised approaches are insufficient to model these activities and a training set of clipped videos for ADL cannot cover all the variations. In addition, since these methods require manually clipped videos, they can only follow an offline recognition scheme. On the other hand, unsupervised approaches are strong in finding spatio-temporal patterns of motion. However, the global motion patterns are not enough to obtain a precise classification of ADL. For long-term activities, there are many unsupervised approaches that model global motion patterns and detect abnormal events by finding the trajectories that do not fit in the pattern [70], [83]. Many methods have been applied on traffic surveillance videos to learn the regular traffic dynamics (e.g. cars passing a cross road) and detect abnormal patterns (e.g. a pedestrian crossing the road) [71].
Proposed Method
We propose a hybrid method to exploit the benefits of both approaches. With limited user interaction our framework recognizes more precise activities compared to available approaches. We use the term precise to indicate that, unlike most of trajectory-based approaches which cannot distinguish between activities under same region, our approach can be more sensitive in the detection of activities thanks to local motion patterns. We can summarize the contributions of this work as following: i) online recognition of activities by automatic clipping of long-term videos and ii) obtaining a comprehensive representation of human activities with high discriminative power and localization capability.
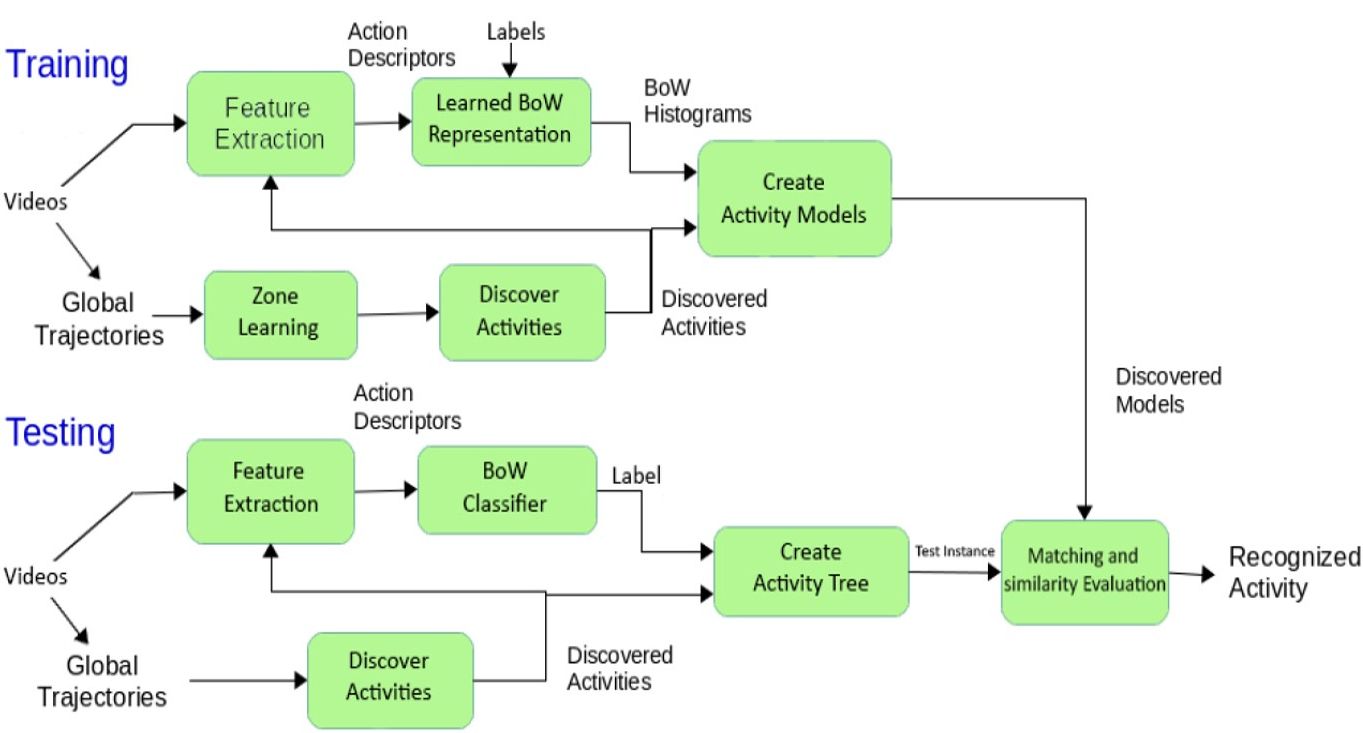
Figure 19 illustrates the flow of the training and testing phases in the proposed framework. For the training phase, the algorithm learns relevant zones in the scene and generates activity models for each zone by complementing the models with information such as duration distribution and BoW representations of discovered activities. At testing, the algorithm compares the test instances with the generated activity models and infers the most similar model.
The performance of the proposed approach has been tested on the public GAADRD dataset [73] and CHU dataset. Our approach always performs equally or better than online supervised approach in [99] (see Table15 and Table16). And even most of the time it outperforms totally supervised approach (manually clipped) of [99]. This reveals the effectiveness of our hybrid technique where combining information coming from both constituents could contribute to enhance recognition. The paper of this work was accepted in AVSS 2016 conference [30].
| Supervised (Manually Clipped) | Online Version | Unsupervised Using | Proposed Approach | |||||
| of [99] | of [99] | Global Motion [66] | ||||||
| ADLs | Recall (%) | Prec. (%) | Recall (%) | Prec. (%) | Recall (%) | Prec. (%) | Recall (%) | Prec. (%) |
| Answering Phone | 57 | 78 | 100 | 86 | 100 | 60 | 100 | 81.82 |
| P. Tea + W. Plant | 89 | 86.5 | 76 | 38 | 84.21 | 80 | 94.73 | 81.81 |
| Using Phar. Basket | 100 | 83 | 100 | 43 | 90 | 100 | 100 | 100 |
| Reading | 35 | 100 | 92 | 36 | 81.82 | 100 | 100 | 91.67 |
| Using Bus Map | 90 | 90 | 100 | 50 | 100 | 54.54 | 100 | 83.34 |
| AVERAGE | 74.2 | 87.5 | 93.6 | 50.6 | 91.2 | 78.9 | 98.94 | 87.72 |
| Supervised (Manually Clipped) | Online Version | Classification by | Unsupervised Using | Proposed Approach | ||||||
| Approach [99] | of [99] | detection using SSBD [49] | Global Motion [66] | |||||||
| ADLs | Recall (%) | Prec. (%) | Recall (%) | Prec. (%) | Recall (%) | Prec. (%) | Recall (%) | Prec. (%) | Recall (%) | Prec. (%) |
| Answering Phone | 100 | 88 | 100 | 70 | 96 | 34.29 | 100 | 100 | 100 | 88 |
| Establish Acc. Bal. | 67 | 100 | 100 | 29 | 41.67 | 41.67 | 100 | 86 | 67 | 100 |
| Preparing Drink | 100 | 69 | 100 | 69 | 96 | 80 | 78 | 100 | 100 | 82 |
| Prepare Drug Box | 58.33 | 100 | 11 | 20 | 86.96 | 51.28 | 33.34 | 100 | 22.0 | 100 |
| Watering Plant | 54.54 | 100 | 0 | 0 | 86.36 | 86.36 | 44.45 | 57 | 44.45 | 80 |
| Reading | 100 | 100 | 88 | 37 | 100 | 31.88 | 100 | 100 | 100 | 100 |
| Turn On Radio | 60 | 86 | 100 | 75 | 96.55 | 19.86 | 89 | 89 | 89 | 89 |
| AVERAGE | 77.12 | 91.85 | 71.29 | 42.86 | 86.22 | 49.33 | 77.71 | 90.29 | 74.57 | 91.29 |